Generic fuzzy-type algorithms use fuzzy matching techniques to identify similarities between data.
They do not take into account the specific context of the data.
By integrating contextual intelligence into our matching process, SCM achieves a superior matching rate. This deep understanding ensures that even the most nuanced or complex matches are identified efficiently.
=> Smart Contextual Matching improves significantly accuracy.
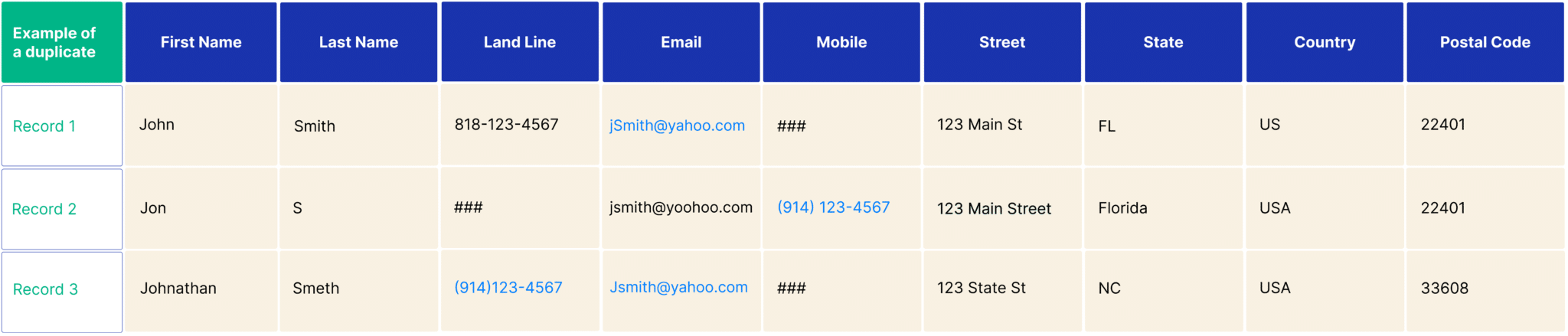
Matching on First Name, Last Name, Mobile, Land Line, Email, Street, State, Country and Postal Code.
Fuzzy Matching uses simple phonetic matching and Levenshtein distance algorithms, it did not match the third record because it could not match on any of the rules.
Smart Contextual Matching:
Smart Contextual Matching employs dynamic distance metrics and sophisticated pattern recognition to evaluate the similarity between data entries. It
matched all three records!
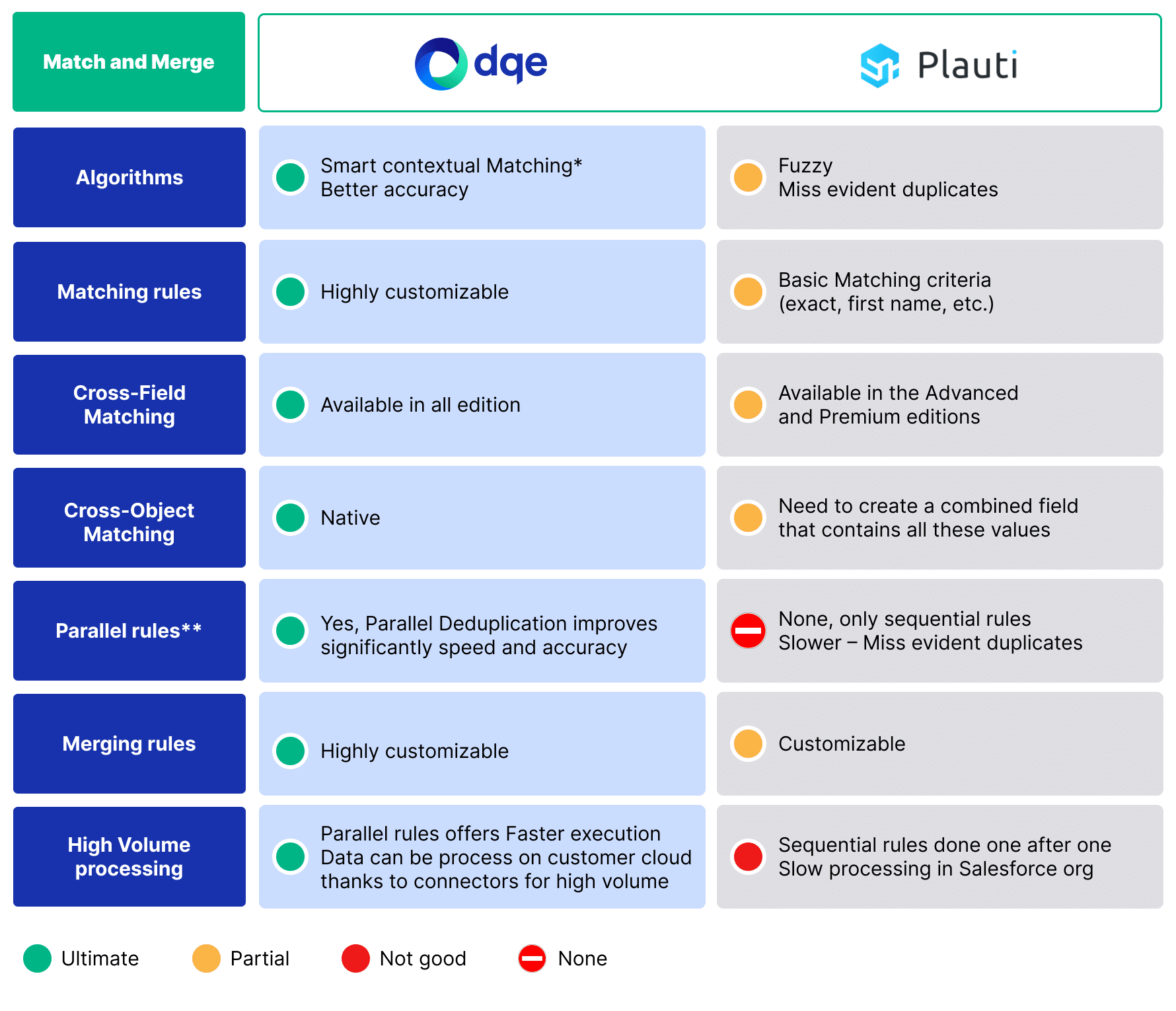
Sequential deduplication processes data one by one, comparing each piece with previously scanned data to identify duplicates.
It follows a linear and single-threaded approach to deduplication.
Parallel deduplication divides data into segments and processes them concurrently across multiple threads.
It combines insights from each rule.
=> Parallel Deduplication improves significantly speed and accuracy.
In sequential deduplication with the initial rule of matching by email, the system initially grouped ‘John Smith‘ with ‘Johnathan Smeth‘ due to their shared email address (‘jSmith@yahoo.com‘ and ‘Jsmith@yahoo.com‘). After removing this duplicate, the system couldn’t link ‘John Smith’ with ‘Jon S’ as they didn’t share a common email or phone.
Result with a Parallel Rules
With parallel deduplication rules, multiple attributes of data entries are compared simultaneously. While one thread matches entries based on email addresses (e.g., ‘jSmith@yahoo.com‘ and ‘Jsmith@yahoo.com‘), another thread simultaneously identifies potential duplicates using other shared attributes like names ‘John Smith‘ and ‘Jon S‘ ,phone numbers ‘(914) 123-4567‘ or address ‘123 Main Street‘.
In the example below, how can reliable contact data be differentiated from unreliable contact data before performing a merge?
The same contact exists in triplicate, to perform intelligent data merging, DataQ verifies reachable contact data.
What DataQ brings to your merge
Single contact records enhanced with reliable contact data.
During deduplication, contact data (Postal Address, email, phone) is checked to determine its reachability.
This process enables the identification of the golden ID and facilitates Smart merging with reliable data by performing quality checks on contact details.