DQE et l'IA, le duo gagnant pour une data quality intelligente et sans compromis
L’intelligence artificielle transforme en profondeur la manière dont les organisations exploitent et gouvernent leurs données. Chez DQE, nous intégrons l’IA au cœur de nos outils pour vous offrir une qualité de données augmentée, fiable et intelligente, capable de s’adapter aux contextes et usages métiers des entreprises, quels que soient leurs domaines d’activités.
Agents IA + Copilot dédié :
votre assistant intelligent en ligne
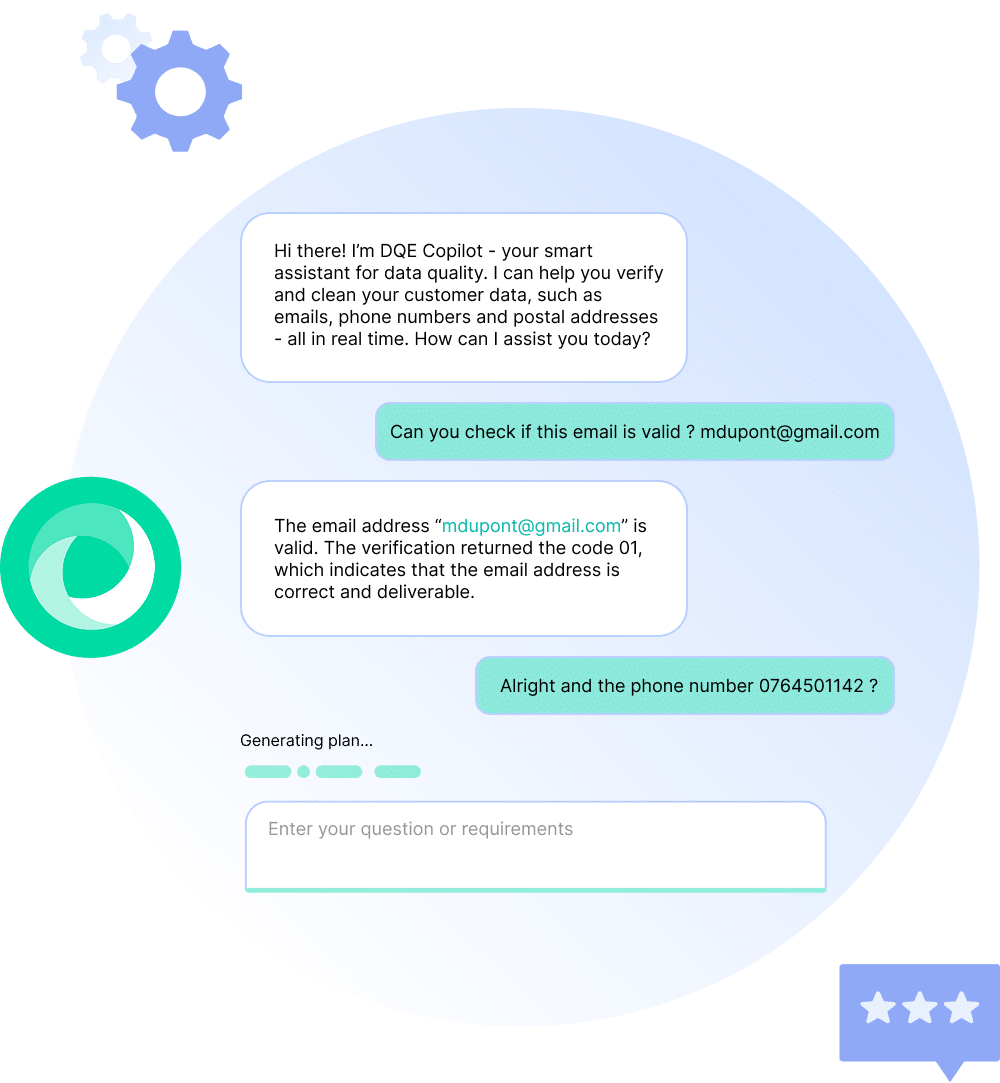
Grâce aux Agents IA DQE intégrés dans nos solutions de qualité de données et à un Copilot dédié, vous disposez d’un véritable assistant en ligne dès le point d’entrée de la data :
Vérification de vos données client en temps réel (email, téléphone, adresse postale etc.)
Détection automatique des anomalies, erreurs, fautes de frappes et incohérences
Explication des erreurs identifiées
Proposition de corrections immédiates
Accompagnement des utilisateurs dans leurs opérations au quotidien
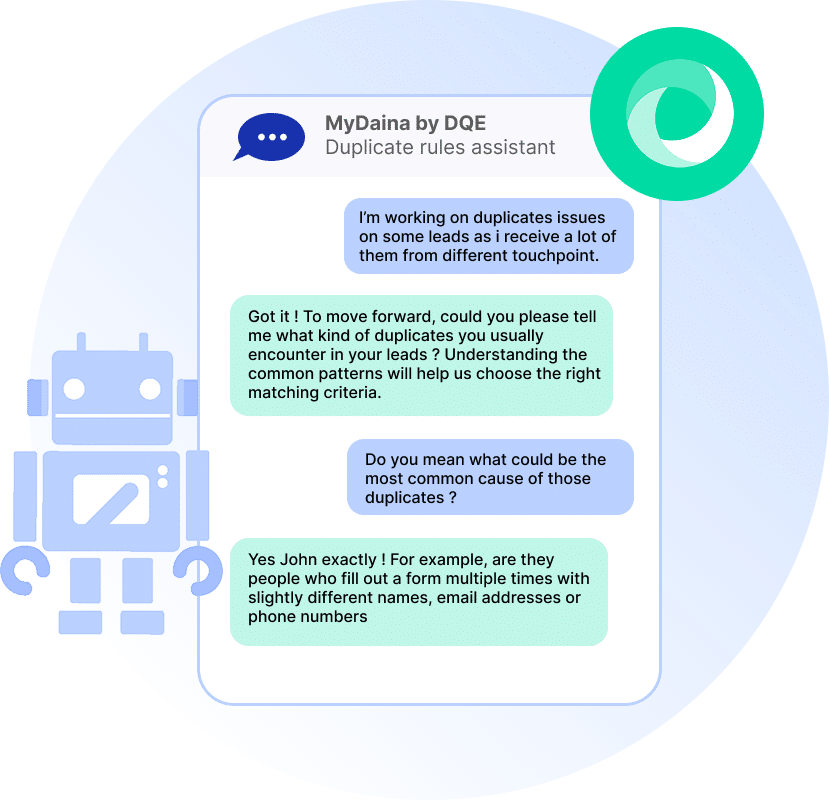
MyDaina, votre assistant IA pour faciliter le dédoublonnage
MyDaina est un moteur d’IA qui vous permet de concevoir et de générer des règles de dédoublonnage sur mesure, en s’appuyant sur vos cas d’usage, vos contraintes métier et vos objectifs opérationnels.
Grâce à une interaction guidée avec l’utilisateur, MyDaina vous accompagne dans la formalisation et la création de règles de paramétrage pertinentes pour vos traitements de dédoublonnage.
Génération assistée de règles de dédoublonnage à partir de votre cas d'usage
Proposition de règles métier basées sur les bonnes pratiques et les scénarios décrits par l’utilisateur
Ajustement et enrichissement des règles au fil des échanges et de l’évolution de vos besoins
Résultats : Avec MyDaina, vous gagnez en efficacité et en maîtrise. Vos règles de dédoublonnage sont plus pertinentes, plus cohérentes et parfaitement alignées avec votre contexte métier.
Livrables et audits de qualité de données : l’IA au service de l’expertise DQE
Nos experts combinent l’IA et leur savoir-faire pour auditer vos fichiers et fournir des recommandations adaptées à vos enjeux de qualité de données client.
Analyse technique et cohérence du fichier (structure, format, colonnes vides ou mal formatées)
Profilage automatique des champs et détection des incohérences
Analyse des métadonnées et des corrélations entre les différents champs
Analyse globale sur la qualité du fichier : L’audit donne une vision claire des principaux points à améliorer en mettant, par exemple, en lumière les taux de champs vides, de données incohérentes ou non pertinentes et les anomalies récurrentes.
Recommandations globales : L’audit met en évidence la démarche ainsi que les solutions à mettre en place pour améliorer durablement la qualité de vos données.
Synthèse finale : elle évalue la structuration, la complétude, la cohérence et le typage de vos données.
Résultats : Vous disposez d’une vision claire, précise et directement exploitable de la qualité de votre fichier pour indentifier les problèmes, comprendre comment les résoudre et définir les actions permettant d’améliorer durablement l’intégrité de vos données.
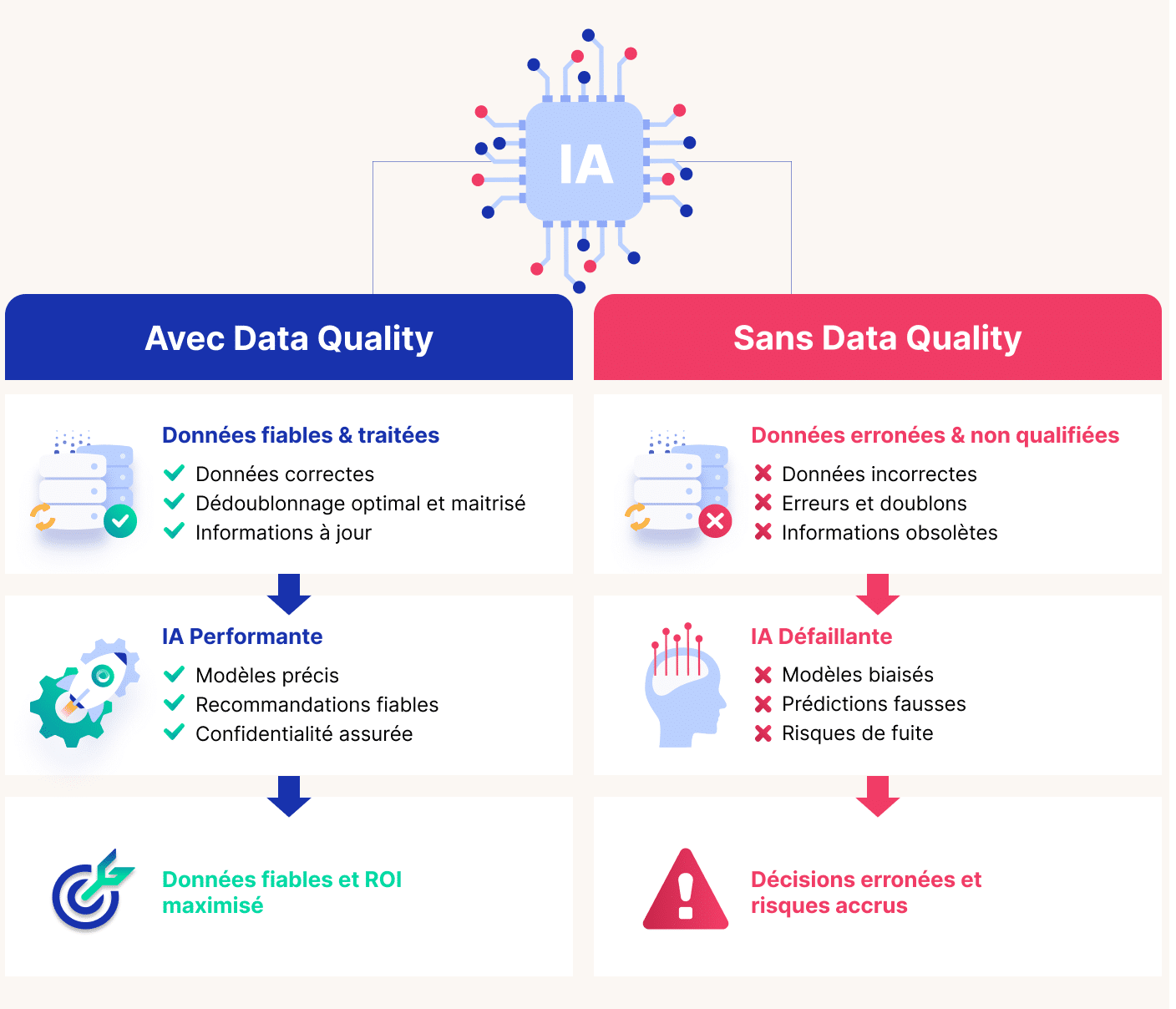
La data quality, un socle indispensable des cas d’usage IA
Les projets d’IA, générative ou prédictive, s’appuient sur des volumes massifs de données pour produire des résultats exploitables. Si ces données sont incomplètes, erronées ou incohérentes, les résultats risquent d’être inutiles, biaisés ou directement trompeurs ; c’est le fameux « Garbage in, garbage out ».
Dans un contexte où l’IA ingère et traite des données à des vitesses et à des échelles sans précédent, la fiabilité des cas d’usage dépend directement de la qualité du socle de données qui les alimente. Par exemple, des erreurs dans les données de contact client (doublons, informations incorrectes ou obsolètes) peuvent fausser la connaissance client et les prédictions automatiques.
Au-delà de l’exactitude des données, des données mal qualifiées peuvent générer des risques opérationnels et compromettre la confiance : réponses biaisées, adoption réduite par les utilisateurs métiers, voire vulnérabilités de sécurité.
C’est pourquoi il est essentiel d’adopter une approche proactive de la Data Quality, intégrant gouvernance solide, culture des données et outils adaptés pour collecter, nettoyer et maintenir des flux qualifiés. Cette discipline améliore les performances des modèles d’IA, renforce la confiance des utilisateurs et maximise l’impact métier.
du temps des équipes IA et data est consacré à un projet au nettoyage et à la préparation des données.
1 sur 2
des modèles n’atteint pas les seuils de performance attendus en production, faute de données suffisamment propres ou complètes.
70%
des projets d’IA échouent principalement à cause de données de mauvaise qualité qui compromettent la fiabilité des résultats.
Pour aller plus loin, découvrez notre Livre Blanc
Qualité des données et IA : le socle invisible de la performance des entreprises
Une certitude s’impose dans toutes les organisations que nous accompagnons : l’IA n’est performante et efficace que si la donnée est fiable. Découvrez des retours terrain, des chiffres clés et une vision claire pour transformer vos données en avantage concurrentiel durable.